
Intro to the Socrata API with the NYC Dog Licensing Dataset & Python
Contents
Intro to the Socrata API with the NYC Dog Licensing Dataset & Python¶
# importing libraries
import pandas as pd
import numpy as np
from sodapy import Socrata
import requests
import plotly.express as px
from urllib.request import urlopen
import json
pd.options.display.max_rows = 100
pd.options.display.max_columns = 50
What is an API?¶
The Socrata API follows the REST (REpresentational State Transfer) design pattern.
REST stands for REpresentational State Transfer. It originally had a more abstract meaning, but has come to be a shorthand name for web sites that act a bit like python functions, taking as inputs values for certain parameters and producing outputs in the form of a long text string.
API stands for Application Programming Interface. An API specifies how an external program (an application program) can request that a program perform certain computations.
Putting the two together, a REST API specifies how external programs can make HTTP requests to a web site in order to request that some computation be carried out and data returned as output. When a website is designed to accept requests generated by other computer programs, and produce outputs to be consumed by other programs, it is sometimes called a web service, as opposed to a web site which produces output meant for humans to consume in a web browser.
Anatomy of a URL with the Socrata API¶
For this demonstration we will be making requests to the Socrata API with the The NYC Dog License Dataset.
Components of the url:
headers (required sometimes, but not always)
endpoints
parameters
API key
In a REST API, the client or application program makes an HTTP request that includes information about what kind of request it is making. Web sites are free to define whatever format they want for how the request should be formatted.
In this format, the URL has a standard structure:
the base URL: https://data.cityofnewyork.us/resource/nu7n-tubp.json
a ? character
or more key-value pairs (parameters), formatted as key=value pairs and separated by the & character
For example, consider the following url requests to the NYC Dog License Dataset with the Socrata API:
https://data.cityofnewyork.us/resource/nu7n-tubp.json?rownumber=40895
https://data.cityofnewyork.us/resource/nu7n-tubp.json?licenseissueddate=2014-09-12T00:00:00.000
https://data.cityofnewyork.us/resource/nu7n-tubp.json?animalname=PAIGE&zipcode=10035
Try copying that URL into a browser, or just clicking on it. Depending on your browser, it may put the contents into a file attachment that you have to open up to see the contents, or it may just show the contents in a browser window.
API Documentation¶
The API documentation for the NYC Dog License Dataset contains all of the parts of the url that we need. The fields in the documentation describe the parameters we can use to filter the data in the url request. It is important to read the API documentation for every dataset you use in NYC Open Data, as each dataset has unique features that need to be considered when making requests.
Application Tokens and API Keys¶
The Socrata Open Data API has two concepts around API access: authentication and application tokens. You only need to authenticate if you wish to add, delete, or modify data that is attached to your account, or if you wish to read data you own that you have marked as private. Read-only requests only require the application token. See the SODA Producer API documentation for more details on changing data. See the API docs for more information on app tokens and API keys. For this example we are requesting data from the API for analysis, so only the application token is needed.
The Socrata Open Data API uses application tokens for two purposes:
Using an application token allows the API to throttle by application, rather than via IP address, which gives you a higher throttling limit
Authentication using OAuth (OAuth 2.0 is the preferred option for cases where you are building a web or mobile application that needs to perform actions on behalf of the user, like accessing data, and the interaction model allows you to present the user with a form to obtain their permission for the app to do so.)
See Generating App Tokens and API Keys for instructions on generating your own app token.
Using the Socrata client to make requests¶
We are using the Python sodapy library to make our request. The client sends our request for the data, and the API sends the data to us in .json format. Then the pandas library is used to format the results into a dataframe. The get() method is used with parameters to filter the data in our request. Check out the SoSQL examples in the sodapy github for more info. The filters use the SoSQL statements, which are based on SQL and have similar syntax.
# Unauthenticated client only works with public data sets. Note 'None'
# in place of application token, and no username or password:
client = Socrata("data.cityofnewyork.us", 'tpwmd1DMwYMlz8q2BgPqJ48Ky')
# Example authenticated client (needed for non-public datasets):
# client = Socrata('data.cityofnewyork.us',
# 'appTOKEN',
# username='username',
# password='password')
# Results returned as JSON from API / converted to Python list of
# dictionaries by sodapy.
results = client.get("nu7n-tubp",
limit=5000,
#where = "extract_year = '2017' AND breedname = 'Boxer'",
where = "breedname = 'Akita'",
#where = "animalname = 'PAIGE'",
select = "animalname, breedname, zipcode, extract_year",
order = "zipcode")
# Convert to pandas DataFrame
doggy_data = pd.DataFrame.from_records(results)
doggy_data['count'] = 1
doggy_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 491 entries, 0 to 490
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 animalname 491 non-null object
1 breedname 491 non-null object
2 zipcode 491 non-null object
3 extract_year 358 non-null object
4 count 491 non-null int64
dtypes: int64(1), object(4)
memory usage: 19.3+ KB
doggy_data.head(20)
| animalname | breedname | zipcode | extract_year | count | |
|---|---|---|---|---|---|
| 0 | TARA | Akita | 10009 | 2016 | 1 |
| 1 | LINK | Akita | 10009 | 2016 | 1 |
| 2 | TARA | Akita | 10009 | 2018 | 1 |
| 3 | TARA | Akita | 10009 | NaN | 1 |
| 4 | LINK | Akita | 10009 | 2018 | 1 |
| 5 | LINK | Akita | 10009 | 2017 | 1 |
| 6 | LINK | Akita | 10009 | NaN | 1 |
| 7 | TARA | Akita | 10009 | 2017 | 1 |
| 8 | SAMA | Akita | 10011 | 2017 | 1 |
| 9 | KUMA | Akita | 10011 | 2018 | 1 |
| 10 | SAMA | Akita | 10011 | 2018 | 1 |
| 11 | SAKURA | Akita | 10012 | NaN | 1 |
| 12 | SHIRO | Akita | 10013 | 2018 | 1 |
| 13 | KOTI | Akita | 10013 | 2017 | 1 |
| 14 | KODO | Akita | 10013 | NaN | 1 |
| 15 | KODO | Akita | 10013 | NaN | 1 |
| 16 | SHIRO | Akita | 10013 | 2017 | 1 |
| 17 | SHIRO | Akita | 10013 | 2016 | 1 |
| 18 | KOTI | Akita | 10013 | 2018 | 1 |
| 19 | DOLCE | Akita | 10014 | 2018 | 1 |
doggy_data['breedname'].unique()
array(['Akita'], dtype=object)
doggy_data['extract_year'].unique()
array(['2016', '2018', nan, '2017'], dtype=object)
Visualize the data with plotly express¶
# create grouped dataframe by count of dog registration by zipcode
doggy_zips_grouped = doggy_data[['zipcode', 'count']].groupby(by = 'zipcode').sum().reset_index()
# use GeoJSON file from NYC opendata which contains GIS data for zip code boundaries in NYC
# web page with info on data set url here:
# https://data.cityofnewyork.us/Health/Modified-Zip-Code-Tabulation-Areas-MODZCTA-/pri4-ifjk
with urlopen('https://data.cityofnewyork.us/resource/pri4-ifjk.geojson') as response:
zip_codes = json.load(response)
fig = px.choropleth_mapbox(doggy_zips_grouped, geojson=zip_codes, locations='zipcode', color='count',
featureidkey='properties.modzcta',
color_continuous_scale="Viridis",
range_color=(0, max(doggy_zips_grouped['count'])),
mapbox_style="carto-positron",
zoom=9.25, center = {"lat": 40.743, "lon": -73.988},
opacity=0.5,
labels={},
title="Number of Dog License Registrations in NYC by Zipcode"
).update(layout=dict(title=dict(x=0.5)))
fig.update_layout(margin={"r":0,"t":30,"l":0,"b":0})
fig.show()
Extracting Data with the Yelp Fusion API¶
The Yelp Fusion API allows you to get the best local content and user reviews from millions of businesses across 32 countries.
Authentication & App Keys¶
The Yelp Fusion API uses private key authentication to authenticate all endpoints. Your private API Key will be automatically generated after you create your app. For detailed instructions, refer to the authentication guide. Follow the instructions in this guide to create an app and receive an app key.
To create an App and API Key:¶
Sign up for an account
Fill out App form
The API Key will be used to query the Yelp Fusion API.
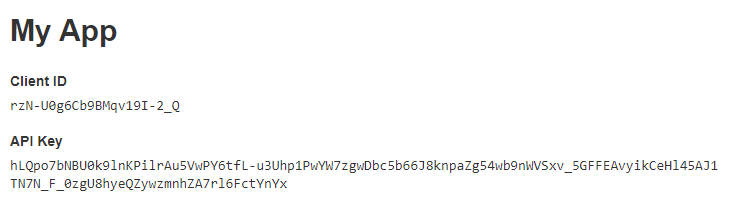
Url Components¶
headers: set the Authorization HTTP header value as Bearer API_KEY, i.e. ‘Authorization’: ‘Bearer {API_KEY}’
endpoints: There are several endpoints under the base url https://api.yelp.com/v3. For our request we will be using the business search endpoint: /businesses/search. Our complete endpoint is https://api.yelp.com/v3/businesses/search. See the Yelp Fusion API docs for a complete list of endpoints.
parameters: for a complete list of parameters that can be used to query the data see the /businesses/search endpoint in the documentation. Some parameters used in our request are:
term
location
categories
offset
limit
Python requests module¶
In Python, there’s a module available called requests. You can use the get function in the requests module to fetch the contents of a page. The requests.get() method will be used to query the API.To authenticate API calls with the API Key, set the Authorization HTTP header value as Bearer API_KEY.
# API only returns 1,000 results and 50 per request
# we use the offset parameter to page through to the next 50
# source: https://www.yelp.com/developers/faq
# saving my api key as an environment variable
# API_KEY = os.environ.get('YELP_API')
# if API_KEY is None:
# config = AutoConfig(search_path = '.')
# API_KEY = config('YELP_API')
API_KEY = 'HZzYHUHDbFqeNYQEiN8Y86945mE-1MKiUFgegyf-2AscR2J1owV1Smb8Vw4vbzkTCsGU1sC0cgwkIMYOB3_Io7OUnSySQ0dlrcW_PjX68HMsnH0K4VTtkVFFhYgBYnYx'
# empty list to place our data for each page
lst = []
# our offset parameter - each page 50 rows
offset = 0
print('initial offset number: {}'.format(offset))
# loop through the api 20 times (limit is 1000 rows with each page includes 50 rows)
for i in range(20):
try:
headers = {'Authorization': 'Bearer {}'.format(API_KEY)}
search_api_url = 'https://api.yelp.com/v3/businesses/search'
params = {
'term': 'bubble tea',
'categories': 'bubbletea',
'location': 'New York City',
'offset': offset,
'limit': 50}
response = requests.get(search_api_url,
headers=headers,
params=params,
timeout=10)
# return a dictionary
data_dict = response.json()
# convert the business dictionary to a pandas dataframe
data = pd.DataFrame(data_dict['businesses'])
# append dataframe to list
lst.append(data)
# add 50 to the offset to access a new page
offset += 50
print('current offset number: {}'.format(offset))
except Exception as ex:
print('exception: {}\nexit loop.'.format(ex))
break
# concatenate all pages to one dataframe
df = pd.concat(lst)
df = df.reset_index(drop=True)
rows, columns = df.shape
print()
print('query includes {:,} rows and {} columns.'.format(rows, columns))
print('row id is unique: {}.'.format(df['id'].is_unique))
if df['id'].is_unique == False:
duplicates = df.loc[df.duplicated(subset=['id'])]
vals = list(duplicates['name'].values) # this said duplicates.head()['name'].values, took out .head() to get all values
print('\nduplicates found: {}.'.format(vals))
df = df.drop_duplicates(subset=['id']).reset_index(drop=True)
print('dropping duplicates...')
rows, columns = df.shape
print('\nrow id is unique: {}.'.format(df['id'].is_unique))
print('query includes {:,} rows and {} columns.'.format(rows, columns))
initial offset number: 0
current offset number: 50
current offset number: 100
current offset number: 150
current offset number: 200
current offset number: 250
current offset number: 300
current offset number: 350
current offset number: 400
current offset number: 450
current offset number: 500
current offset number: 550
current offset number: 600
current offset number: 650
current offset number: 700
current offset number: 750
current offset number: 800
current offset number: 850
current offset number: 900
current offset number: 950
current offset number: 1000
query includes 554 rows and 16 columns.
row id is unique: True.
df.head()
| id | alias | name | image_url | is_closed | url | review_count | categories | rating | coordinates | transactions | price | location | phone | display_phone | distance | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Q3fmTHT7zilDWtfzLK9lMA | truedan-new-york-3 | Truedan | https://s3-media2.fl.yelpcdn.com/bphoto/BmUZXO... | False | https://www.yelp.com/biz/truedan-new-york-3?ad... | 99 | [{'alias': 'bubbletea', 'title': 'Bubble Tea'}] | 4.5 | {'latitude': 40.7191742, 'longitude': -73.9962... | [delivery, pickup] | $$ | {'address1': '208 Grand St', 'address2': None,... | +16465592886 | (646) 559-2886 | 1535.241614 |
| 1 | bVJQEeRNi34-3XN_F1AZEg | xing-fu-tang-new-york | Xing Fu Tang | https://s3-media2.fl.yelpcdn.com/bphoto/cyFHFE... | False | https://www.yelp.com/biz/xing-fu-tang-new-york... | 91 | [{'alias': 'bubbletea', 'title': 'Bubble Tea'}] | 4.5 | {'latitude': 40.7288, 'longitude': -73.98775} | [delivery, pickup] | NaN | {'address1': '133 2nd Ave', 'address2': '', 'a... | 2656.450427 | ||
| 2 | 7-bx74TooPuZKZDNW4WFcQ | chun-yang-tea-new-york | Chun Yang Tea | https://s3-media1.fl.yelpcdn.com/bphoto/JrGwrZ... | False | https://www.yelp.com/biz/chun-yang-tea-new-yor... | 91 | [{'alias': 'bubbletea', 'title': 'Bubble Tea'}] | 4.5 | {'latitude': 40.71617, 'longitude': -73.9971} | [delivery, pickup] | $$ | {'address1': '26B Elizabeth St', 'address2': '... | +12124200123 | (212) 420-0123 | 1212.877370 |
| 3 | 3aypSFXLfkAL4dhHVFobKg | lazy-sundaes-new-york-6 | Lazy Sundaes | https://s3-media3.fl.yelpcdn.com/bphoto/kEfCYC... | False | https://www.yelp.com/biz/lazy-sundaes-new-york... | 32 | [{'alias': 'bubbletea', 'title': 'Bubble Tea'}... | 4.5 | {'latitude': 40.720597, 'longitude': -73.984539} | [delivery, pickup] | $$ | {'address1': '23 Clinton St', 'address2': None... | 1877.016204 | ||
| 4 | zupVwJAFYkHDwrsQd2ktXA | fiftylan-union-square-new-york-3 | FIFTYLAN Union Square | https://s3-media3.fl.yelpcdn.com/bphoto/UIwR20... | False | https://www.yelp.com/biz/fiftylan-union-square... | 60 | [{'alias': 'bubbletea', 'title': 'Bubble Tea'}] | 4.0 | {'latitude': 40.735516, 'longitude': -73.989191} | [delivery, pickup] | NaN | {'address1': '32 Union Square E', 'address2': ... | +16467670085 | (646) 767-0085 | 3367.900728 |
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 554 entries, 0 to 553
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 554 non-null object
1 alias 554 non-null object
2 name 554 non-null object
3 image_url 554 non-null object
4 is_closed 554 non-null bool
5 url 554 non-null object
6 review_count 554 non-null int64
7 categories 554 non-null object
8 rating 554 non-null float64
9 coordinates 554 non-null object
10 transactions 554 non-null object
11 price 335 non-null object
12 location 554 non-null object
13 phone 554 non-null object
14 display_phone 554 non-null object
15 distance 554 non-null float64
dtypes: bool(1), float64(2), int64(1), object(12)
memory usage: 65.6+ KB
Visualize the data¶
# create grouped dataframe by count of dog registration by zipcode
loc_df = pd.concat([df, df['location'].apply(pd.Series)], axis=1)
loc_df['count'] = 1
loc_df_grouped = loc_df[['name','zip_code','count']].groupby(by = 'zip_code').sum().reset_index()
# use GeoJSON file from NYC opendata which contains GIS data for zip code boundaries in NYC
# web page with info on data set url here:
# https://data.cityofnewyork.us/Health/Modified-Zip-Code-Tabulation-Areas-MODZCTA-/pri4-ifjk
with urlopen('https://data.cityofnewyork.us/resource/pri4-ifjk.geojson') as response:
zip_codes = json.load(response)
fig = px.choropleth_mapbox(loc_df_grouped, geojson=zip_codes, locations='zip_code', color='count',
featureidkey='properties.modzcta',
color_continuous_scale="Viridis",
range_color=(0, max(loc_df_grouped['count'])),
mapbox_style="carto-positron",
zoom=9.25, center = {"lat": 40.743, "lon": -73.988},
opacity=0.5,
labels={},
title="Number of Boba Tea Shops in NYC by Zipcode"
).update(layout=dict(title=dict(x=0.5)))
fig.update_layout(margin={"r":0,"t":30,"l":0,"b":0})
fig.show()
# scatter_plot with plotly express
coordinates_df = pd.concat([df, df['coordinates'].apply(pd.Series)], axis=1)
fig = px.scatter_mapbox(coordinates_df,
lat='latitude',
lon='longitude',
hover_name=None,
hover_data=['name'],
color_discrete_sequence=['goldenrod'],
zoom=9,
title='Boba Tea Shops in NYC',
size_max = 0.1).update(layout=dict(title=dict(x=0.5)))
fig.update_layout(mapbox_style="carto-positron")
fig.update_layout(margin={"r":0,"t":30,"l":0,"b":0})
fig.show()
Further data exploration¶
Where are the cheapest Boba Tea shops located in NYC? (hint: use the price parameter to filter the API query)
Which Boba shops in NYC have the highest rating?
Which Boba shops in NYC have the most ratings?